研究プロジェクト

視覚言語モデルとの非言語インタラクション
現在の大規模言語モデルや視覚言語モデルは主に自然言語による指示に依存しており、人間のコミュニケーションの重要な要素である非言語情報を十分に活用できていないという課題があります。本研究では、視線、ジェスチャー、表情などの身体的表現を言語モデルへの入力モダリティとして統合し、より直感的で自然なHuman-AIインタラクションの実現を目指しています。身体動作そのものをAIに対する入力指示として扱える基盤技術の開発により、言語に頼らない多様なコミュニケーション様式を可能にし、AIシステムのアクセシビリティと包摂性の向上に取り組んでいます。
Large Language Models
Vision-Language Models
Human-Computer Interaction
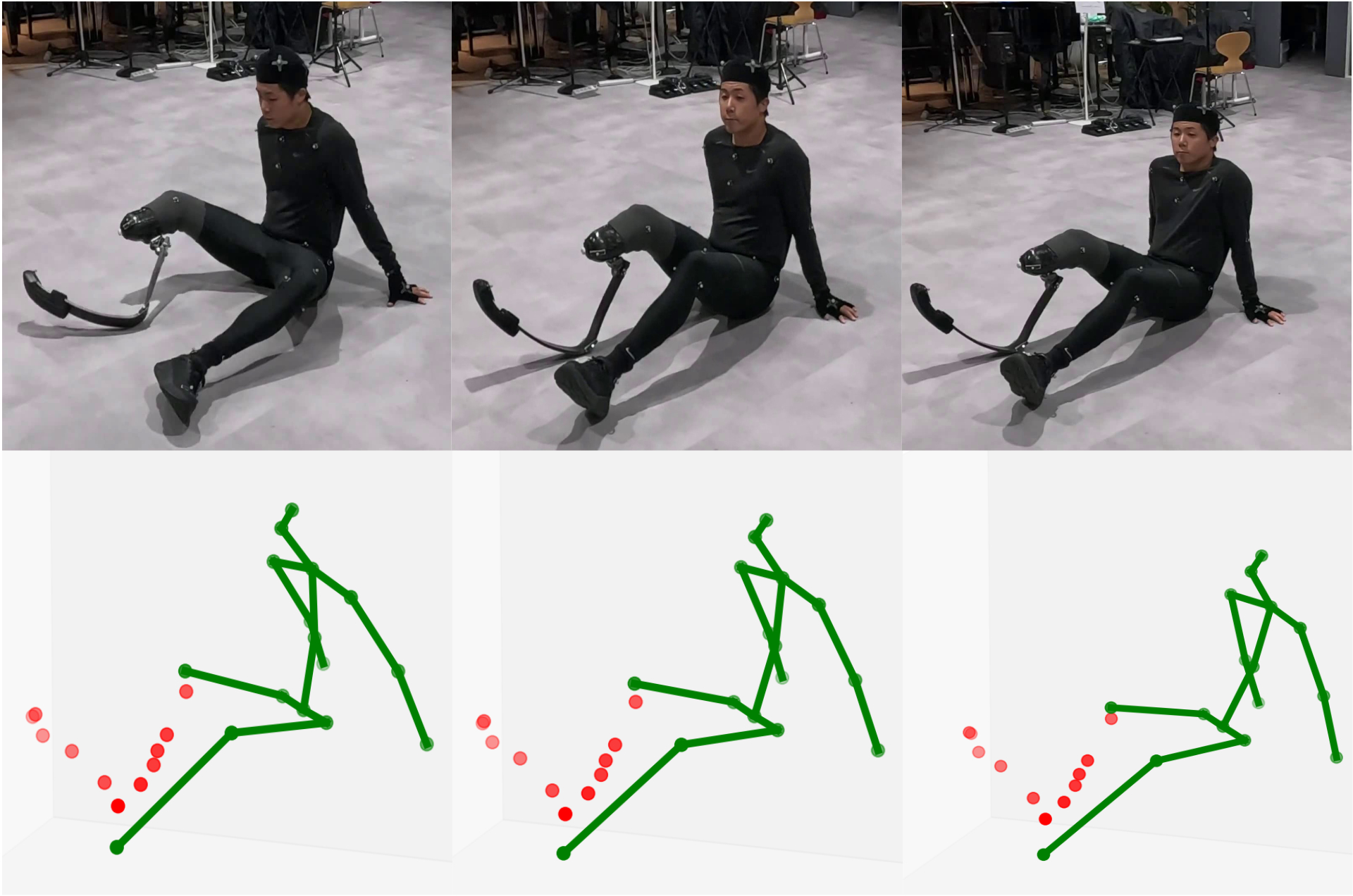
義肢利用者のための包摂的3次元姿勢推定
現在の姿勢推定技術は「標準的」な身体を前提としており、義肢利用者を含む多様な身体特性を持つ人々が技術から排除されているという根本的な課題があります。本研究では、統計的機械学習モデルと個人の多様性のギャップという本質的な問題に取り組み、義肢利用者のための新しい姿勢推定技術の開発を進めています。技術開発と並行して、当事者との対話と共創を重視したプロセスを構築することで、AI技術開発における包摂性の実現を目指しています。
Computer Vision
Participatory Design
xDiversity

ゲーミフィケーションを通した参加型訓練データ収集
機械学習モデルの性能向上には大規模で質の高い訓練データが不可欠ですが、従来のデータ収集手法は単調な作業の繰り返しとなりがちで、参加者のモチベーション維持が課題となっています。本研究では、データ収集プロセスをゲーム要素と組み合わせることで、参加者が楽しみながら質の高いデータを提供できる枠組みを構築しています。視線推定や画像認識タスクにおいて、プレイヤー間の協調的なゲームプレイを通じて多様な言語記述や行動データを収集し、同時に参加者のAI技術への理解と関心を深める参加型研究基盤の実現に取り組んでいます。
Machine Learning
Participatory Design

非専門家向けインタラクティブ機械学習
画像認識や機械学習にもとづくシステムをデザインする上で、訓練済みモデルの応用を考えるだけでは不十分なケースは数多く存在し、ユーザ自信が自分なりの認識モデルを主体的に設計できる枠組みが重要になります。本研究室では、ツールとしての機械学習を一般ユーザに開かれたものにするために、インタラクティブな機械学習環境を実現するための可視化手法・インタフェース設計やワークショップを通した分析など、システムの開発とユーザ評価・検証実験を通してこの課題に挑戦しています。
Machine Learning
Human-Computer Interaction
xDiversity

アピアランスベース視線推定
環境の中で人がどこを見ているかを認識することで、注意に関連する人間の内部状態推定や人の注意に応じた柔軟な情報提示などの様々な応用が実現できます。従来の視線推定は専用のハードウェアを必要とする手法が主流でその応用範囲が限られていましたが、私達は大規模な訓練データセットと機械学習によりカメラ画像のみを入力とした視線推定手法を開発しています。
Computer Vision
Machine Learning